bien

jueves, 26 de abril de 2012
Cátedra UNESCO de Educación a Distancia (CUED): Integrando las TIC en Educación... hoy (versión 2.0)
Cátedra UNESCO de Educación a Distancia (CUED): Integrando las TIC en Educación... hoy (versión 2.0)
domingo, 22 de abril de 2012
Comparación de Medias con SPSS.
1. Medias:
Este procedimiento permite (particionar) tiene como finalidad calcular una serie de estadísticos (media, numero de caso, desviación típica, mediana, entre otras.) de una o mas variables (dependent List), para los distintos valores, niveles o categorías de una o mas variables (independent List). Para ello se trabajara con el archivo Técnico.sav, cuyas variables para el ejemplo son dias: los dias trabajados durante un semestre natural. La variable visita: visitas realizadas por ese mismo grupo de técnicos a lo largo de dicho semestre. Y la variable zona lugar de trabajo de ellos.


Hacer click en opciones, luego continuar, aceptar:

2. Una Muestra
Con este procedimiento se trata de comprobar la hipótesis nula (Ho) de la no existencia de diferencias significativas entre la media de una muestra (en este caso 64 técnicos) y un parámetro poblacional. La empresa a la que pertenecen los técnicos tiene establecido 125 días laborables durante todo el semestre. Se pretende contrastar el promedio de días trabajado por los técnicos con respecto a los días del parámetro poblacional dado.


Hacer click en opciones, luego continuar, aceptar:

Se puede observar que los 64 técnicos de la muestra han trabajado un promedio (media) de 111,73 días, con una desviación típica de 9,943 ( existe una variación en el numero de días trabajados por unos y otros de los técnicos). La media de días trabajados por esta muestra de técnicos esta 13,27 horas por debajo del valor teórico establecido (125). Con una t= -10,673 y con una significanció de la prueba de 0,00, y 63 grados de libertad (df) . se puede concluir que existe diferencia significativa entre el estadístico (111,73) y el parámetro (125).
3. Muestras Pareadas
Se trata de constrastar la hipotesis nula de la no existencia de diferencias significativas ente las medias de dos muestras, pero en este caso se trata de datos apareados:
Se deben considerar dos situaciones a saber:
3.1 Que sean los mismos sujetos en dos situaciones diferentes salario1 y salario dos.
3.2 Que sean sujetos distintos en ambos grupos pero comparables par a par con respecto a una variable.



Ejercicio:
Se desea saber si existe diferencia de criterio entre dos profesores, respecto a la calificación de un examen escrito. Para eso se hace calificar a cada profesor, separadamente, los exámenes escritos de 14 alumnos. Las calificaciones aparecen en la tabla. Determine si existe diferente criterio entre los profesores para colocar la nota. Use nivel de significación 0,05.


Envíeme los resultados.(escuelaplana@gmail.com).
3. Dos Muestras con datos Independientes:
Con este procedimiento se trata de comprobar la hipótesis nula (Ho) de la no existencia de diferencias significativas entre las medias de dos muestras distintas de individuos. Por ejemplo se pretende estudiar si la variables salario difieren o no, en función del estado civil de los técnicos (casado, soltero).


En el caso de variable de agrupación, definir grupo 1 (casado); 2 (soltero).


De acuerdo a los resultados no existe diferencias significativas. Envíenme el razonamiento.
(escuelaplana@gmail.com).
Ejercicio:
Se dan dos dietas distintas a dos grupos de chivos asignados aleatoriamente a esas dietas, para probar si la ganancia de peso con la dieta A difiere significativamente de la ganancia de peso con la dieta B. Las ganancias de peso en kilos en determinado tiempo se observan en la tabla. Pruebe si existen diferencias estadísticamente significativas.

SPSS:- Analizar- Comparar medias- Prueba T para muestras independientes:
Envíenme todo el proceso, resultados y el razonamiento. (escuelaplana@gmail.com).
jueves, 19 de abril de 2012
Errores, Sesgos, Tipos.
1) ERROR SISTEMÁTICO:
En un estudio analítico puede producirse en la inducción de sujetos en el estudio, en su asignación a los grupos de tratamiento y en la recogida, análisis, interpretación, publicación y revisión de los datos.
2) ERROR DE TIPO I:
Consiste en rechazar una hipótesis nula, siendo ésta verdadera. El error alfa es el error que se comete cuando se rechaza una hipótesis nula cuando ésta verdadera. La probabilidad alfa es la probabilidad de cometer un error de tipo I. Es costumbre fijarla en a = 0,05, es decir en una probabilidad del 5%.
3) ERROR DE TIPO II:
Consistente en aceptar una hipótesis nula, siendo ésta falsa. El error beta es el error que se comete cuando no se rechaza una hipótesis nula siendo ésta falsa. La probabilidad beta es la probabilidad de cometer un error de tipo II. Es costumbre fijarla en un 10% (de modo que 1- β = 0,90) o bien en un 20% (de modo que 1- β = 0,80). El término 1-β es el poder estadístico del estudio.
Error sistemático, variante del sesgo de información, debido a la recogida selectiva de datos, de manera consciente o inconsciente, por parte del entrevistador. (con el fin de limitarlo se usan cuestionarios estructurados).
Error sistemático resultante de medir la exposición (estudios de casos y controles) o la evolución (estudios de cohortes y en ensayos clínicos no a ciegas) con diferente intensidad entre los dos grupos comparados.
Diferencia sistemática entre el valor real y el registrado. En un ensayo clínico el más común es el debido al conocimiento, por parte del observador, del tratamiento recibido por cada sujeto.
Forma de sesgo de selección, resultante de creer que los ensayos (y otros estudios) publicados son los realmente realizados. Muchos ensayos clínicos no son publicados (porque no terminan, porque el investigador considera irrelevantes sus resultados, porque el promotor no lo desea o bien porque no son aceptados para publicación). Eso ocurre especialmente con los ensayos clínicos que no registran diferencias entre los distintos grupos de tratamiento.
8) SESGO DE SELECCIÓN:
Error sistemático consecuencia de que las características de los sujetos incluidos en un estudio son diferentes de las características de los no incluidos, de modo que la muestra no es representativa de la población de referencia.
miércoles, 18 de abril de 2012
Análisis Multivariante con SPSS: Regresión Lineal
El análisis de regresión lineal es una técnica estadística que se utiliza para estudiar la relación entre variables. Suele emplearse para pronosticar valores en una variable criterio (dependiente, explicada, (Y)), desde las puntuaciones en una variable predictora (independientes, explicativas(x)). Cuando se estudia una sola variable predictora se denomina regresión simple. Sin embargo la regresión también puede efectuarse a partir de 2 o más variables predictoras (independiente X1, X2, etc.) denominadas regresión múltiple.
En otras palabras se denomina regresión lineal simple, a aquélla en la que aparece una sola variable independiente y regresión lineal múltiple, cuando aparece más de una variable independiente en la ecuación de la regresión.
Ejemplo: Regresión Lineal Simple
¿Están relacionados el consumo a los 120 Km/h de un todo terreno con la cilindrada que posee?. Se pretende determinar una expresión matemática (ecuación) que permita predecir el consumo de los vehículos todo terreno a los 120 Km/h a partir de las cilindradas de los mismos.




Estimado Profesor Castro, no se le olvide lo que conversamos, antes de aplicar la regresión, se debe verificar los requerimientos básicos: linealidad, normalidad, colinealidad, independencia de las observaciones etc.
martes, 17 de abril de 2012
Estadística Multivariante con SPSS
Esta entrada, es parte de una respuesta, por una consulta realizada por el Profesor Jhony Castro, relacionada con el análisis multivariante.
MODELO LINEAL GENERAL COMPONENTES DE LA VARIANZA


Se presentan a continuación un paso a paso, para realizar un Manova con el spss, mediante el siguiente ejemplo donde se comparan tres métodos de enseñanza, en cuanto a: su utilidad, su dificultad e importancia.
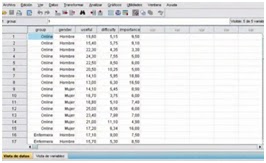











lunes, 16 de abril de 2012
Estructura del SPSS: Barras de Menús
El SPSS contienen 10 menús desplegables que permiten controlar la mayoría de las acciones que realiza. Se presenta a continuación los más utilizados:
Menú Archivo:
Permite crear archivos de datos y de sintaxis, abrir y guardar todo tipo de archivos, importar / exportar archivos desde / a otros programas, imprimir archivos, recuperar archivos recientemente utilizados, entre otros.

Menú Edición:
Permite editar (cortar, copiar, pegar, buscar, etc.) el contenido de un archivo; luego puede deshacer y rehacer acciones de edición, insertar variables o casos; ir a un caso concreto; y modificar algunas de las especificaciones iniciales (opciones) con las que arranca el programa.

Menú Ver:
Permite controlar el aspecto de las distintas ventanas del SPSS. Así, permite mostrar/ocultar la barra de estado, personalizar la barra de herramientas, editar los diferentes menús, seleccionar el tipo y el tamaño de las fuentes utilizadas. Además, el Editor de Datos permite controlar el aspecto de las celdas (con cuadrícula o sin ella) y mostrar/ocultar las etiquetas de los valores. Finalmente, en el Visor de Resultados, este menú se utiliza para mostrar/ocultar resultados concretos y para contraer/expandir bloques de resultados.

Menú Datos:
Contiene funciones propias del Editor de Datos, tales como ordenación de casos, transposición de filas y columnas, segmentación del archivo, selección de casos del archivo, agregación de filas o de columnas nuevas, y otros.

Menú Transformar:
Permite crear variables nuevas a partir de las ya existentes, para cambiar los valores de las variables, para reemplazar los valores perdidos, para recodificarlas, para crear series temporales, y otras.

Menú Analizar:
Es el Menú más importante de SPSS, porque contiene todas las operaciones estadísticas que pueden realizarse con este programa, desde simples análisis descriptivos hasta sofisticados análisis multivariantes, pasando por pruebas no paramétricas, por el análisis de series temporales, por análisis de regresión, etc.

Menú Gráficos:
Permite generar todo tipo de gráficos, a partir de los datos de las variables contenidas en el archivo de datos. Entre las posibilidades que ofrece este menú se encuentran los gráficos de barras, de sectores, de líneas, histogramas, diagramas de dispersión, otros.

PD: Si deseas detallar mejor, las imágenes de este blogger, hazle un clic sobre ella.
domingo, 15 de abril de 2012
Selección de Casos con SPSS.
En una población, hay veces que se necesita hacer una selección de determinados casos o individuos, en función de una característica en particular, tales como el genero (masculino, o femenino), el grado de instrucción, (primaria, básica, media, universitaria) u otros. E inclusive una muestra de un porcentaje de caso (muestra) con respecto a la población. El SPSS permite realizar esta selección utilizando criterios diferentes:
1. Selección de una muestra aleatoria.
2. Selección de un número determinado de casos.
3. Selección de los casos que verifiquen una determinada condición.
Selección de una muestra aleatoria:

Se marca en el espacio que le corresponde a muestra aleatoria de casos.

Se marca en "aproximadamente" y se coloca el porcentaje, en este caso el 30%.


Las tachaduras indican, que esos casos no fueron seleccionados, para la muestra aleatoria del 30%. Posteriormente se ejecuta el comando Frecuencias o Descriptivas ya explicado en la entrada de codificación.
Codificación de Datos en SPSS
La profesora Chiquinquira Franco desea procesar mediante el SPSS, los datos recopilados en un breve diagnóstico sobre su actuación en el uso de una dinámica de cohesión social en una clase de Dibujo Técnico, tomando en cuenta a la variable género del alumno: hombre y mujer y a la opinión sobre su actuación como docente cuya escala de estimación oscila entre 1: muy mala, 2: mala, 3: aceptable, 4: buena, 5: muy buena. Los datos en cuestión son los siguientes:
Genero
|
Opinión sobre su actuación docente
|
Hombre
|
5
|
Hombre
|
3
|
Hombre
|
3
|
Mujer
|
4
|
Mujer
|
4
|
Mujer
|
4
|
Mujer
|
4
|
Mujer
|
3
|
Hombre
|
5
|
Mujer
|
4
|
Mujer
|
4
|
2. Luego en vista de variables se debe configurar cada variable, según una serie de elementos o parámetros: Nombre, tipo, anchura…

3. Posteriormente después de configuradas las variables se pasa a vista de datos para introducir los mismos.
4. Para evitar sorpresas se debe grabar (Archivo, guardar como) la plantilla recién creada con el nombre ejemplo.sav
5. Seguidamente se puede ya implementar el primer procesamiento sencillo. Por ejemplo se puede calcular las frecuencias de cada una de las variables.


Tras desarrollar los pasos anteriores y tras activar aceptar debe aparecer estos resultados:

Finalmente, se debe posicionarse sobre cada tabla, se activa el botón derecho y la opción “copiar”. Luego se debe ir al procesador de textos “el Word, por ejemplo” y se pega la tabla, para su posterior análisis..
Suscribirse a:
Comentarios (Atom)